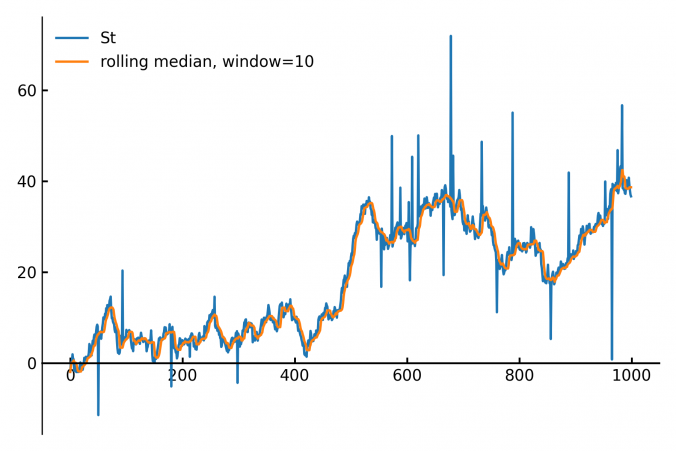
Calculating the median of data points within a moving window is a common task in fields like finance, real-time analytics and signal processing. The main applications are anomal- and outlier-detection / removal.
A naive implementation based on sorting is costly—especially for large window sizes. An elegant solution is the Two-Heaps Rolling Median algorithm, which maintains two balanced collections to quickly calculate the median as new data arrives and old data departs.
This algorithm keeps two data structures:
- Lower half (max-heap): stores the smaller half of the window’s data points.
- Upper half (min-heap): stores the larger half of the window’s data points.
By carefully balancing these two halves at every step, the median is always accessible with minimal computational effort. Typically, inserting or removing elements and rebalancing the two halves can be done efficiently, achieving a time complexity of  , where
, where  is the window size.
is the window size.
Here’s how it works step by step:
- Insert the new element:
- If the new element is smaller or equal to the maximum of the lower half, insert it into the lower half.
- Otherwise, insert it into the upper half.
- Remove the oldest element:
- Find and remove it from the half where it currently resides.
- Rebalance:
- Adjust the two halves so their sizes differ at most by one element. The lower half either has the same number of elements as the upper half or exactly one more.
- Compute median:
- If the halves are equal in size, the median is the average of the largest value from the lower half and the smallest from the upper half.
- If not, the median is the largest value from the lower half.
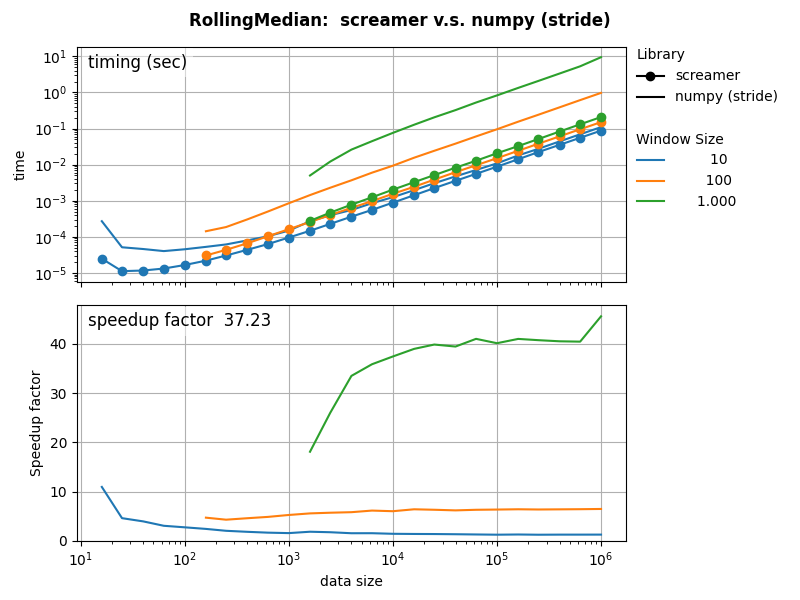
A C++ version of this algorithm in our screamer library executes 1mln rolling median queries on streaming data, with a windows size 1000, in 0.2 sec. The speedup compared to numpy and a stided trick is a factor 37.
Below Python code!
import bisect
from collections import deque
import numpy as np
class RollingMedian:
def __init__(self, window_size):
if window_size <= 0:
raise ValueError("Window size must be positive.")
self.window_size = window_size
self.buffer = deque(maxlen=window_size)
self.low = [] # Lower half (max-heap behavior via reverse sorting)
self.high = [] # Upper half (min-heap)
def reset(self):
self.buffer.clear()
self.low.clear()
self.high.clear()
def add(self, value):
# Remove old value if buffer is full
if len(self.buffer) == self.window_size:
self._remove(self.buffer.popleft())
self.buffer.append(value)
# Add new value
self._insert(value)
def median(self):
if not self.low and not self.high:
return np.nan
if len(self.low) == len(self.high):
return (self.low[-1] + self.high[0]) / 2.0
else:
return self.low[-1]
def _insert(self, value):
# Insert into low or high
if not self.low or value <= self.low[-1]:
bisect.insort(self.low, value)
else:
bisect.insort(self.high, value)
self._rebalance()
def _remove(self, value):
# Remove from low or high
idx = bisect.bisect_left(self.low, value)
if idx < len(self.low) and self.low[idx] == value:
self.low.pop(idx)
else:
idx = bisect.bisect_left(self.high, value)
if idx < len(self.high) and self.high[idx] == value:
self.high.pop(idx)
self._rebalance()
def _rebalance(self):
# Keep low either equal or exactly one more element than high
while len(self.low) > len(self.high) + 1:
bisect.insort(self.high, self.low.pop())
while len(self.high) > len(self.low):
bisect.insort(self.low, self.high.pop(0))