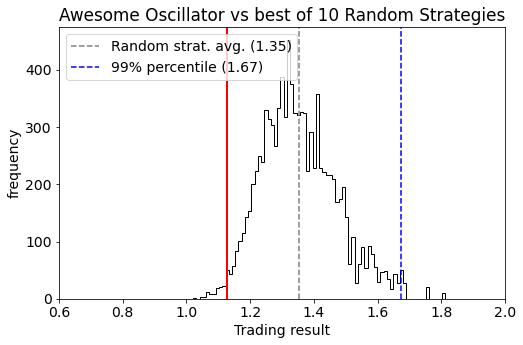
Back-testing trading strategies is a dangerous business because there is a high risk you will keep tweaking your trading strategy model to make the back-test results better. When you do so, you’ll find out that after tweaking you have actually worsened the ‘live’ performance later on. The reason is that you’ve been overfitting your trading model to your back-test data through selection bias.
In this post we will use two techniques that help quantify and monitor the statistical significance of backtesting and tweaking:
- First, we analyze the performance of backtest results by comparing them against random trading strategies that similar trading characteristics (time period, number of trades, long/short ratio). This quantifies specifically how “special” the timing of the trading strategy is while keeping all other things equal (like the trends, volatility, return distribution, and patterns in the traded asset).
- Second, we analyse the impact and cost of tweaking strategies by comparing it against doing the same thing with random strategies. This allows us to see if improvements are significant, or simply what one would expect when picking the best strategy from a set of multiple variants.
![\[L(x) = \frac{1}{2}e^{-|x|} \approx \frac{1}{n} \sum_{i=1}^n N\left(x | \mu=0, \sigma^2=-2\ln \frac{1+2i}{2n}\right)\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-246c45086d7e5b5efa7aae119e530e72_l3.png "Rendered by QuickLaTeX.com")