The Current Market Shake-Up
Last week, global stock markets faced a sharp and sudden correction. The S&P 500 dropped 10% in just two trading days, its worst weekly since the Covid crash 5 years ago.
Big drops like this remind us that market volatility isn’t random, it tends to stick around once it starts. When markets fall sharply, that volatility often continues for days or even weeks. And importantly, negative returns usually lead to bigger increases in volatility than positive returns do. This behavior is called asymmetry, and it’s something that simple models don’t handle very well.
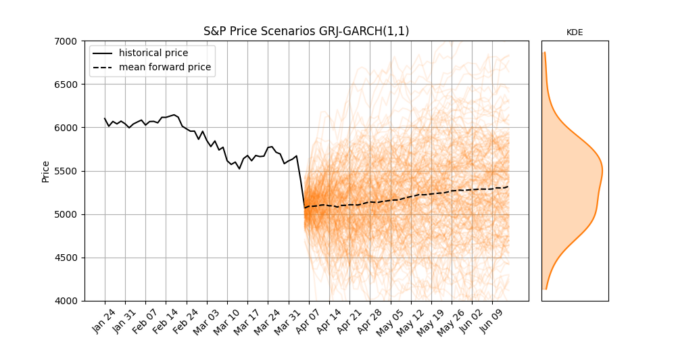
In this post, we’ll explore the Glosten-Jagannathan-Runkle GARCH model (GJR-GARCH), a widely-used asymmetric volatility model. We’ll apply it to real S&P 500 data, simulate future price and volatility scenarios, and interpret what it tells us about market expectations.
Continue reading