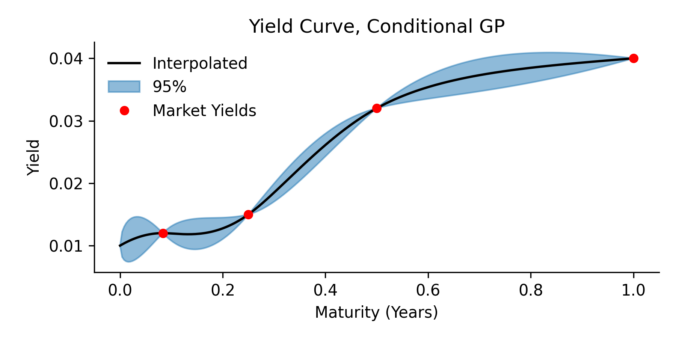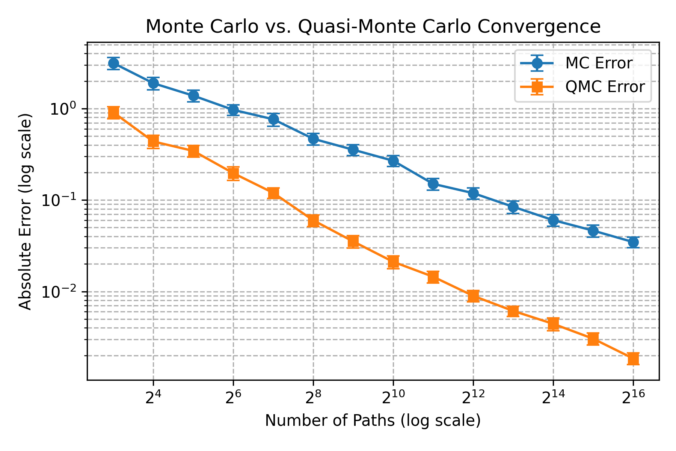
pip install cgmm
I’ve released a small, lightweight Python library that learns conditional distributions and turns them e.g. into scenarios, fan charts, and risk bands with just a few lines of code. It’s built on top of scikit-learn (fits naturally into sklearn-style workflows and tooling).
Example usage:
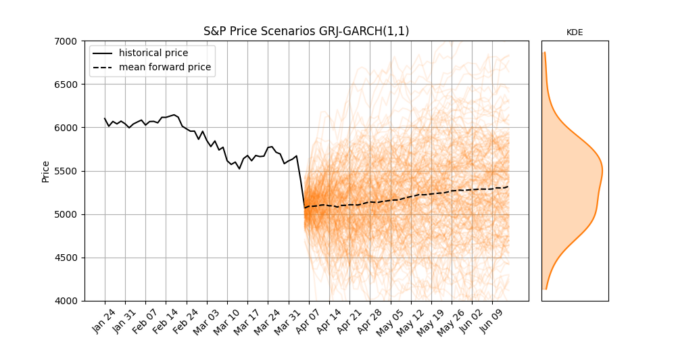
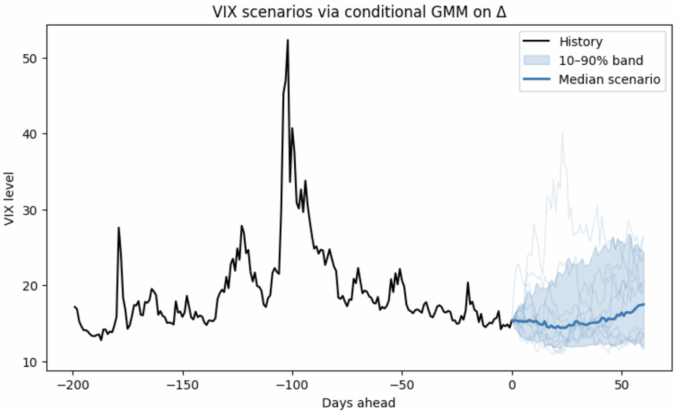
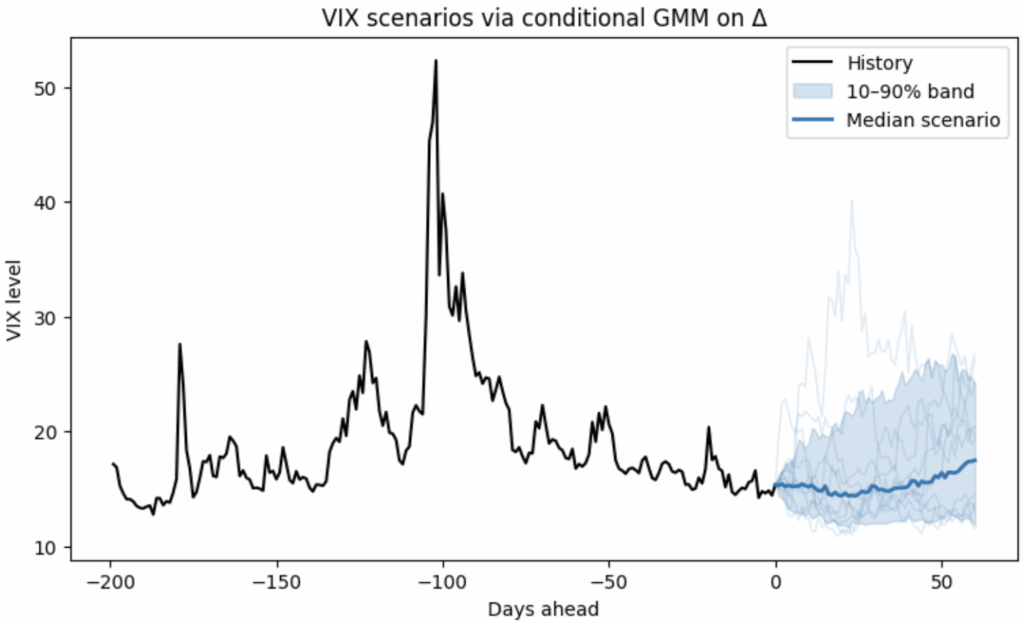
In the figure below, a non-parametric model is fit on ΔVIX conditioned on the VIX level, so it naturally handles:
- Non-Gaussian changes (fat tails / asymmetry), and
- Non-linear, level-dependent drift (behavior differs when VIX is low vs. high).
Features:
- Conditional densities and scenario generation for time series and tabular problems
- Quantiles, prediction intervals, and median/mean paths vuia MC simulation
- Multiple conditioning features (macro, technicals, regimes, etc.)
- Lightweight & sklearn-friendly; open-source and free to use (BSD-3)
VIX example notebook: https://cgmm.readthedocs.io/en/latest/examples/vix_predictor.html
Call for examples & contributions:
- Do you have a use-case we should showcase (rates, spreads, realized vol, token flows, energy, demand, order-book features…)?
- Send a brief description or PR—examples will be attributed.
- Contributions, issues, and feature requests are very welcome. And if you find this useful, please share or star the repo to help others discover it.
Not investment advice. The library is still work in progress!